Hoy vamos con una de SEO que lleva entre borradores ya más de un año. Vamos a hablar del «Crawl Budget» y de su gestión en los sitemaps más complejos para ello: los listados. ¿Qué podemos hacer para guiar a las arañas de la forma más eficiente posible y así mejorar nuestra indexación en consecuencia nuestro posicionamiento. ¿Vamos?
Qué es el Crawl Budget
Este es un concepto de Indexación que viene a definir cuanto tiempo dedican los robots de Google a rastrear nuestro site y sacar información de él. Cada web tiene asignado un Crawl Budget distinto, es decir, a cada web Google le destina un tiempo distinto para analizarla. Este tiempo viene determinado por varios factores, la mayoría relativos a lo que solemos llamar Autoridad del site. En otras palabras la mayor parte de los factores que afectan a tu posicionamiento en relación a tu competencia también afectan al Crawl Budget.
¿Cómo podemos saber nuestro Crawl Budget?
Lo mejor que podemos hacer es acudir a Google Search Console. Dentro de este tenemos un informe muy útil aunque poco detallado que encontramos en en «Rastreo >> Estadísticas de Rastreo».
En esta sección encontraremos un informe como el que sigue:
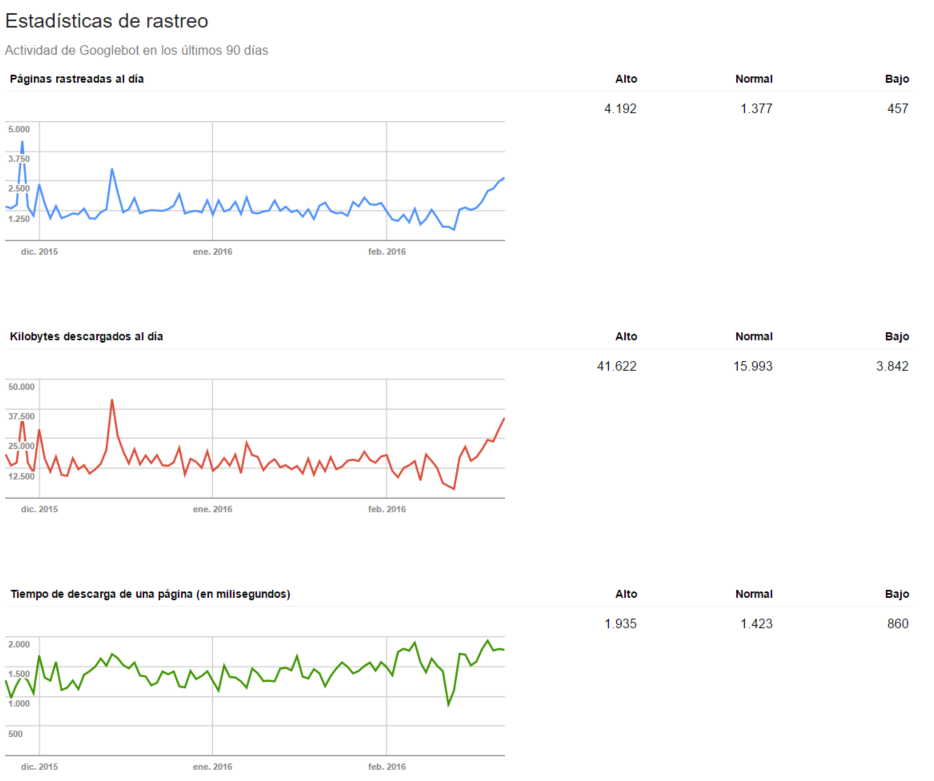
Y que nos describe 3 conceptos relacionados directamente con el Crawl Budget (aunque ninguno llega a definirlo directamente)
- Páginas rastreadas al día: Es la información que más nos interesa, pero la menos relacionada con el tiempo dedicado por Google. Nos indica cuantas páginas (URLs Únicas) han visitado las arañas de Google cada día
- Kilobytes rastreados al día: Ya no nos habla de páginas sino del peso de estos archivos. Es decir, cuanta información recoge sobre nosotros al día Google
- Tiempo de descarga de una página: Nos permite unir los otros dos conceptos y terminar de redondear la información sabiendo la media de tiempo que tarda un el robot en descargar como media las páginas
Al final la métrica que realmente queremos no la tenemos (que sería tiempo dedicado por las arañas a tu site por día) y es que Google nunca nos pone las cosas del todo fácil. Para rascar un poco más deberíamos irnos al analisis de Logs que a pesar de existir casi desde el principio de las webs se ha vuelto a poner de moda este último año.
Lo que si tenemos que tener claro, como comentaba antes, que ese tiempo es más o menos estable y varía de la misma forma que lo hace la autoridad de tu site. Existen excepciones a esto que basicamente se resumen en que cuando Google detecta que tiene mucho trabajo de indexación por delante (migraciones, caidas de la web, cambios de diseño, etc.) suele esforzarse un poco más y subir tu crawl budget un tiempo, al menos hasta que entienda que vuelve a tener controlada la situación.
Sea como sea, esta situación nos lleva a que no hace falta que destinemos esfuerzos a mejorar el Crawl Budget de Google pues ya estamos haciendo ese mismo trabajo por otras vías (AI, LinkBuilding, LinkBaiting, Branding, etc.).
Donde tenemos que trabajar es en optimizar ese Crawl Budget para sacarle más partido
Las ventajas de ser Rastreado
Para tener claro que debo optimizar lo primero es entender que objetivo persigo con ello. ¿que busco al gestionar de forma eficiente mi Crawl Budget?
Existen varias posibles ventajas, unas que no son discutibles y otras de esas en las que pones a 10 seos a discutir sobre ellas y tienes no 10 sino 11 o 12 opiniones distintas.
En la parte indiscutible tenemos nuestras necesidades de indexación del site:
- Indexación de lo importante: Es normal que Google no recoja o priorice todas las páginas de nuestro site… ¿sorpresa? No tanto… En webs pequeñas no suele haber problemas, pero en grandes sites muchas veces la cantidad de páginas que ofrezco al buscador es superior a las que mi Crawl Budget me permite indexar. A veces no las vemos todas por temas de contenido duplicado pero en muchas otras ocasiones directamente el contenido no queda indexado en Google. Estas páginas no tienen ni siquiera la oportunidad de aparecer en los resultados de búsqueda por lo que tenemos una perdida de oportunidad de ser encontrados importante con ellas
- Otra factor importante es la frecuencia de refresco del contenido. En páginas profundas GOogle puede tardar mucho tiempo en asimilar los cambios que hemos provocado y eso entorpece nuestro trabajo
En la parte más discutible sobre el rastreo de páginas tenemos
- Ciertas voces que opinan que ser más rastreado aporta más autoridad. Es decir que el hecho de que las arañas pasen mucho por una URL supondría que esa URL gane más autoridad. A mi esta teoría no me convence porque no hay forma de valorar si se trata de correlación o causalidad. ¿Que es lo que sucede realmente? 1. ¿Que aumento mi autoridad y por eso gano más rastreo en la URL? o 2. ¿Que al aumentar el rasteo (con técnicas parecidas a las que aumentan la autoridad) gano más autoridad? Si bien yo creo más en lo primero no son pocos SEOs los que argumentan a favor de la segunda opción…
- Otra de las teorías nos dice que el numero de cambios de la web condiciona más el rastreo que la autoridad. Es cierto que los cambios afectan pero yo no he visto grandes diferencias de rastreo entre webs muy dinámicas y webs prácticamente estáticas en autoridades similares (todo y que como sabemos intuir que dos webs tienen autoridad similar es muy difícil)
Sea como sea, os lo creáis o no, estas dos posibles ventajas también tenemos que tenerlas en cuenta. Es como las señales sociales, nos dicen que no afectan, pero a ver quien va a hacer ascos a unas cuantas menciones desde Twitter o el cada vez más extinto Google+.
Cómo optimizar tu Crawl Budget
¿Qué puedo optimizar de todo esto? Pues volviendo a los gráficos que teníamos antes y aplicándoles un poco de lógica tengo varias palancas que tocar. Intentare resumirlas a modo de listado.
Mejorar la velocidad de carga supone mejorar el número de páginas rastreadas al día
Y esto es de cajón. Si decimos que Google nos destina X tiempo diario a rastrear nuestra web, cuanto más fácil se lo pongamos mejor aprovecharemos ese tiempo. En conclusión, si una página tarda la mitad de tiempo en cargar que otra y tenemos el mismo Crawl Budget debería rastrearnos el doble de páginas vistas.
Esto no es del todo cierto, pues hay parte del proceso de indexación que no es relarivo a la carga sino al proceso que hace Google del HTML pero si que existe una relación directa entre ambas métricas. ¿Y cómo afecto a la velocidad de carga? Bueno, para eso solo hay 2 vías: o hacemos que el servidor sirva más datos en menos tiempo o hacemos que las páginas pesen menos. Sea lo que sea estamos en el terreno del WPO.
En el siguiente gráfico tenéis un ejemplo de como afectamos al número de páginas rastreadas al día con cambios de WPO:
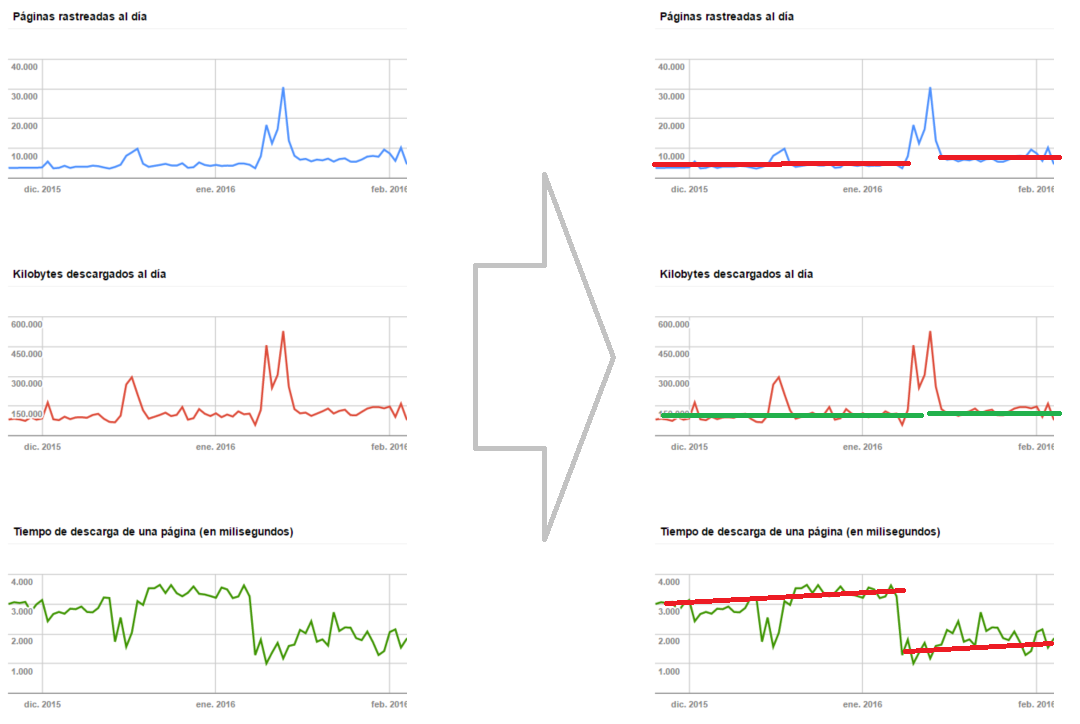
Lo que veis es un site que ha realizado una migración. En esta se han mejorado los tiempos de respuesta del servidor y de paso se ha bajado un poco el peso de las páginas. Las gráficas por si solas tienen tan poco detalle que cuesta ve más allá de que tras la migración se nos ha aplicado un aumento del Crawl Budget temporal hasta que Google ha recogido el nuevo site. A partir de ahí vemos los cambios en nuestras métricas donde observamos:
- Que el tiempo de descarga de las páginas ha bajado sensiblemente.
- El número de KB descargados al día ha subido un poco, esto se debe al cambio de respuesta del servidor que ahora sirve en menos tiempo más datos.
- Y El número de páginas rastreadas al día ha aumentado, no parece mucha distancia pero si nos fijamos hablamos de entre un 20% y un 40% de incremento en páginas indexadas, lo que se dice pronto.
-
Rel next y Prev (documentación)
Solo aplica a paginaciones. Es lo que pide Google que hagamos con ellas, pero no ahorra crawl budget ni aporta mucho aparte del control de duplicidades (vamos que no indexe pagina 2, pero el tiempo lo pierde igual). - noindex,follow. (documentación)
A la antigua, mejora algo el crawl budget pero pasa menos autoridad a los links que contiene. Incluso menos que con un Rel=»next/prev» - canonical hacia pagina sin ese filtro (documentación)
Te cargas la indexacion del filtro o de la página (la tienes que conseguir por otro lado)
Lo que si haces es mejorar algo de crawl budget.
Por otro lado contradices las indicaciones de Google pues el contenido en realidad no es el mismo, pero vamos, no veo que te puedan decir gran cosa por hacer algo así. - robots.txt con urls tipo «page=» (documentación)
Al bloquear el acceso a la araña arreglas el Crawl Budget en su mayor parte.
Es la forma más bruta de hacerlo, así te cepillas de un tiro toda indexación posible de estas páginas. - Directamente gestionar esos links con envios por POST o gestión de cookie (documentación)
Arreglas el Crawl Budget del todo, pero no puedes provocar esas urls para campañas de marketing ni para nada que no sea el propio buscador.
Solo con esta técnica no evitas la indexación salvo que realmente no permitas las visualizaciones por GET .
Por otro lado. ¿Se podría considerar cloaking a una URL que ofreces limpia pero que ofrecer contenido cambiado por el envio por detras de cookie? Difícilmente pero es una puerta que no apatece abrir. - Marcar en Google Search Console esos parámetros como que no afectan al contenido (documentación)
Al final al hacer esto estás mintiendo a Google. Lo que pasa es que al hacerlo funciona. Al menos parcialmente.
Arreglas algo el crawl budget, pero resulta dificil cuantificar en qué medida. - Marcar en Google Search Console esos parámetros filtran o reordenan el contenido (documentación)
Otra vez es en teoría lo que deberíamos hacer si queremos ser 100% correctos pues así le decimos claramente que esas variables son filtros.
Sin embargo, según mi experiencia es como el rel=»next/prev», es lo que toca hacer, pero haciéndolo no arreglas nada. El tiempo de indexación lo pierdes igual y sigues perdiendo indexación en muchas páginas.
Eliminar URLs del rastreo, supone garantizar el rastreo de otras
De esta forma si evito que los robots pierdan tiempo por contenido que se que no me va a aportar visitas o directamente soy consciente de que caerá en el saco de contenido duplicado lo que estoy haciendo es facilitar la indexación de páginas donde si tengo negocio que rascar.
Así que gran parte del trabajo en optimización pasa por delimitar que partes de nuestra web queremos indexar.
Aumentar links (internos o externos) hacia una página aumenta el rastreo de la misma
Por último ya llegando al detalle, cuantos más links incluyamos hacia una página más parte de nuestro Crawl Budget se destinara a la misma. Esto supone que podemos definir distintas tipologías de páginas y forzar que unas sean rastreadas con mayor seguridad que otras «simplemente» variando nuestros links internos o jugando con la famosa estructura web o artquitectura de la información.
Cada una de estas líneas de trabajo como vemos va a tener unas dificiltades y nos será más o menos útil en distintos casos a los que nos enfrentemos.
Llegamos al caso práctico: la indexación de listados y filtrados de contenido
Como ejemplo vamos a tomar una de las partes de la web que más problemas suele ofrecer: la indexación de listados complejos.
Creando el camino de la araña
El primer problema que solemos encontrarnos con esta parte es dotar de vías de rastreo a las arañas. Esto no lo hemos tratado en este post, pero no tiene demasiada complejidad: para que un contenido sea accesible necesitamos que una araña pueda llegar a él y la mejor vía para esto es que en otra página a la que ya accedan las arañas aparezcan links directos hacia las nuevas que deben descubrirse.
En las paginaciones de listados (listados con pagina 1, 2, 3, etc) Esto no suele tener mayor problema: añadimos estas paginaciones como links y la araña ya tiene una vía para acceder a ellos.
En los filtrados (reordenaciones por distintos criterios, filtros por distintas categorías o tipologías, distintas formas de visualizar el listado, etc.) ya podemos tener ciertos problemas. Para que la araña llegue a ellos necesitamos que todo sean links y muchas veces por defecto nos ofrecen estos recursos con elementos de formulario o con programaciones javascript a medida que las arañas tienen muchas dificultades para seguir.
Así que el primer paso es conseguir que nuestros listados (al menos los que nos aporten algo) sean indexables y eso muchas veces ya supone cierto trabajo onpage definiendo links y filtros internos.
Si quieres aprender un poco sobre esto tienes este viejo post (que cortitos eran los posts entonces… :P) con 4 nociones sobre el tema:
>> El arte de los filtros y las categorías
Detectando problemas en el Crawl Budget
Supongamos que ya estamos en el escenario ideal donde las distintas categorías ya han sido transformadas en links y el camino para la araña esta totalmente listo. Ahora es cuando nos podremos encontrar con problemas de Crawl Budget. Miramos que páginas son las que va a indexar el buscador y nos encontramos con una salvajada de opciones, esto pasa… He tenido sites con apenas 50 o 100 productos de los que a partir de los links de listados se rastrean más de 40.000 urls distintas, muchas de ellas totalmente inútiles. ¿Cómo? Pues a base de serguis links de filtrado (los mismos que provocabamos en el paso anterior) que al sumar distintas opciones van multiplicando las urls de listado…
Pensemos solo en un listado donde tenemos:
– Paginaciones (hasta 14 páginas de 5 productos cada una)
– Categorizacion por tipologías (8)
– Categorización por zonas (6)
– 3 modos de visualizacion (3)
– Ordenar por distintos criterios (4)
– De forma ascendente o descendente (2)
Si multiplicamos las posibilidades nos salen más de 15.000 posibles URLs y eso sin contar errores de ordenación de los parámetros que pueden hacer más grave el problema. Para colmo una gran cantidad de las mismas tienen contenido prácticamente duplicado y la diferenciación de titles y descripcións sabemos que va a ser mínima.
En consecuencia, vamos a perder gran parte de nuestro Crawl Budget en la carga de listados… ¿Qué hacemos?
Planificando la optimización del crawl budget
Simpre debemos jugar con todas las herramientas disponibles, antes las hemos enumerado asi que podemos verlas una a una:
WPO
Tenemos que mejorar las velocidades de carga de las páginas. Para esto decíamos que podíamos operar a nivel de servidor y de página.
En el servidor parte del problema va a venir por el tiempo de carga en procesar estas consultas complejas con tantos criterios, para solucionarlo nada mejor que una caché que mantenga estas selecciones como míminmo unos minutos y permita deolver todas estas páginas en milisegundos, si puede ser desde la propia RAM del servidor.
En la parte de front los problemas serán de dos tipos: mejoras de la maqueta (minimización, revisión de etiquetas inutiles, sprites css, etc.) y evitar la sobrecarga de elementos pesados como imágenes y vídeos, eliminando los que podamos y haciendo asíncrona la carga de los más molestos y/o menos perceptibles.
Todo muy técnico pero muy útil también.
Priorización de páginas
Para poder saber qué páginas nos interesa más indexar nos vemos obligados a analizar que páginas rastreables existen. Para ello hacernos con un crawler (por ejemplo Screaming Frog) nos ayudará mucho, pues nos aportará el listado de las páginas existentes. Los análisis de logs tambien pueden ser útiles aunque corremos el riesgo de no llegar con ellos a páginas que si que existen pero que hace mucho que ningún bot o usuario solicita.
Una vez tenemos nuestro listado de URLs rastreables tenemos que priorizarlas por criterios SEO:
En cuanto al posicionamiento de las propias páginas debemos preguntarnos:
– ¿Qué valor tienen las visitas que puedan llegar a esas páginas?
– ¿Qué oportunidades tengo de posicionarlas por alguna keyword?
– ¿Qué capacidad tengo de diferenciarlas o de asignarles keywords distintas?
Y en cuanto a cuanto aportan estas páginas a otras (por ejemplo las de productos)
– ¿Qué links ofrecen estas páginas?
– Y ¿Qué necesidad tengo de que las arañas vean esos links?
Link Sculpting: Jugando con los links
Una vez tengo mis páginas priorizadas es el momento de jugar con los links. Aquí podemos hacer gran parte del trabajo simplemente provocando los links hacia las páginas más interesantes se repitan en todas las páginas de listados mientras que las poco relevantes solo obtengan links en capas más profundas de la web. También tenemos la oportunidad de simplemente eliminar links hacia ciertas zonas aunque al hacer esto hay que tener mucho cuidado con no caer en cloaking (encubrimiento al mostrar distinto contenido a usuarios que a arañas) y en otras técnicas penalizables precisamente por ser formas de engañar a las arañas.
Más interesante si cabe es jugar con las directrices de indexación, buscando la forma más idonea para tu proyecto de provocar que las arañas simplemente no entren en todo ese contenido que para ti no tiene ninguna prioridad. Sabemos que existen una gran cantidad de vías por las que manipular la indexación de un site y guiar a las arañas. Hace no demasiado hice unas tablas de recursos de indexación que a día de hoy siguen vigentes para resumir todas nuestras opciones.
Al final, la gran duda es ¿cual uso para cada caso? Y sobre eso quizas hay suficiente migua como para poner un post completo pero intentaré hacer un resumen…
Tal y como yo lo veo hay 2 problemas distintos:
1) Paginación
– Aquí sueles querer que el bot pase al menos unas pocas paginas (pero no hasta la 30 y menos hasta la 200)
– Pero que consuma el minimo tiempo posible
2) Filtrados y categorizaciones
– Donde tendremos parámetros que no queremos indexar
– Y otros que si quremos y no tocaremos.
Lo dicho, al final se trata de ver que hacemos con los que no queremos indexar de entre todas las posibilidades que tenemos…
Vías de no indexación en listados… ¿Cual usar?
Suponiendo que ya hemos analizado que páginas nos aporta indexar y cuales no tenemos que trabajar esa desindexación o al menos esa reducción del crawl budget en beneficio de otras páginas.
Hay varias posibles soluciones:
Ya veis, ¿no hay ninguna opción 100% buena verdad?
Mi solución particular…(y solo mia)
Os comento lo que yo hago normalmente en sites grandes:
– Rel Next y prev para paginaciones.
– Evitar por robots la indexación a partir de la página X (dependiendo del catalogo, pero normalmente no pasar de 5)
– Limitación por robots.txt o, si no se puede, Canonical en todas las urls de filtros que no acaben de aportarte nada.
– Y parámetros marcados como que no afectan al contenido en las mismas urls.
Esto suponiendo que no tengamos un problema grave de Crawl Budget, que no siempre existe esa suerte y hay webs donde las arañas se vuelven locas.
En webs donde el problema es muy gordo suele ser más efectivo tirar de robots.txt y bloquear la inmensa mayoría de filtros directamente (además de eliminarles los links, si es posible)
Para gustos colores
La verdad es que experiencias hay miles pero siempre son un poco distintas y lo que funciona en un proyecto no lo hace tan bien en otro.
¿Vosotros que hacéis? ¿Creéis que hay alguna forma especialmente mejor o peor que las demás de gestionar el Crawl Budget? Seria genial oírlo, os espero en los comentarios!
7 respuestas a “Indexación Seo: Optimizando el ‘Crawl Budget’ en Listados y Filtrados”
Hola Iñaki. Tengo un par de dudas y reflexiones.
-rel=next y rel=prev ¿no crees que solo tienen sentido para blogs? Para el listado de un catalogo veo poco valor en q indexe mas alla de la primera pagina, al no ser contenido único el que se lista;
-¿importa de cara al priorizado de urls en el rastreo el orden en el que se ordenen las urls en el sitemap? Sería logico;
-¿Ayuda usar preload/… en links internos a Googlebot? Podría ser o no.
🙂
Hola Ant! Intento darte mi opinión.
La indexación de paginaciones en catálogos es interesante solo por el propio litado de links que tiene cada pagina y que Google debe ver para i dexar todo el catalogo.
Por eso la gente usaba noindex,follow que en teoría se reemplaza por rel=next/prev . la idea detrás de ambas técnicas es esa: «no me lo cuentes como pagina pero sigue los links»
El problema es que al hacerte caso pierdes igualmente crawl budget pues tiene que ver la pagina para seguir los links.
La mejor solución? Pues no dejarle ver (con robots.txt o eliminando paginación) si la indexación queda garantizada por otro lado. Por donde queda garantizada? Pues depende de cada pagina… Las que están bien hechas con sus categorías y tags cubren todos los productos y ahí si que no hace falta paginar pero cuando ese control no lo tienes no te queda otra que dejar que el robot pase por ahí aunque sea solo a leer links.
Sobre sitemaps. Lo que afecta es el valor priority que le ponga que precisamente sirve para restar prioridad a paginas que no quieres que estén al mismo nivel que otras.
La última pregunta pues no la entendí 😛
.
ccAnt
-¿Ayuda usar preload/… en links internos a Googlebot? Podría ser o no.
Creo que haces referencia a los links que se pueden ejecutar con Javascript con atributos onclick y si estoy en lo cierto, NO, no ayudan a Googlebot.
Una forma de comprobarlo puede ser mirando la landing en versión cache/solo texto y comprobar si se puede acceder a ese enlace a través de la landing en versión solo texto.
Opino igual sobre la mejor solucion que indicas. Garantizar indexacion via sitemap.xml y listo. Pienso ademas que un sitemap es muy util para darle urls absolutas al robot por si en el codigo se prefiere usar urls relativas por mantenibilidad.
La prioridad, cierto! No recordaba eso en los sitemaps. 🙂
La ultima pregunta/reflexion es que pienso que permitir la precarga de links quizas pueda acelerar el proceso de rastreo y renderizacion una vez ha comenzado. En caso de que paralelice en parte alguna fase.
Yo no he dicho eso Ant!
Garantizar la indexacion solo con sitemaps.xml no es garantizar nada. Con garantizar la indexación me refiero a que siempre ofrezcas links hacia todas las páginas. Si puedes garantizar que no te hace falta paginar para que todos tus productos reciban links desde catalgo entonces puedes eliminar la indexación de páginas. El problema es que esa garantía no siempre la tienes.
Ejemplo: tengo un catalogo de 2000 productos que se subdividen en 5 niveles de categorizaciones a los que ademas se les une una colección de 200 tags.
Parece que las condiciones son idoneas para que no necesites paginaciones para que la araña encuentre links hacia tu producto pero ¿puedes garantizar que ninguno se te escape? De primeras con esa informació no. Podria haber 20 productos muy parecidos que acaben en el mimso nivel de categorización y tengan todos el mismo tag por lo que la araña se perderia parte de estos.
Por otro lado, si confias solo en que con tu sitemap los productos sigan indexados te llevarás alguna sorpresa desagradable. Sitemap es solo una guía, no es buena para provocar indexación por si sola.
Cuanto a la precarga de links, sigo sin saber 100% a que te refieres. Supongo que te refieres a la directiva rel=»preload» que indica al navegador que debe meter en cache ese contenido tras la carga de la página porque es muy probable que se necesite. Sinceramente dudo que esto afecte lo más minimo al rastreo. Para empezar porque es un atributo destinado a contenidos no HTML (js, css, imágenes, fuentes, etc.) y por lo tanto poco tiene que hacer con páginas nuevas. Luego es una directiva destinada a la forma de cargar del browser y no sobre el rastreo. Si ya conseguimos poco efecto con directivas tipo rel=»home» o rel=»tag» o rel=»bookmark» que si son atributos que jerarquizan los documentos en el html no veo porque esta que no va destinada a pesos de página debería afectar. Pero son todo suposnciones, la verdad es que no he hecho la prueba.
Por otro lado Si hablas de provocar el preload con JS tipo jquery mobile, etc. ya estamos hablando de implementaciones no estándar y que requieren de interpretar mucho js para conocerlas. Sabemos que Google llega al onload/onready del documento pero solo para ver si un texto aparece o no en pantalla. No parece que tenga ningún efecto el contenido cargado y luego no usado en el HTML (y ahi si que he hecho pruebas).
Interesante aporte Iñaki
Una consulta con respecto a si actualizas mediante el Blog, digamos una vez por semana, tendrá menos posibilidad de rastreo que se actualizas el blog dos veces por semana o realmente no influye tanto este tipo de actualización?
Gracias por compartir
Saludos
Buenas Roberto,
Si bien nadie va a saber decirte exactamente como afecta si que es cierto que a webs dinamicas se les suele dedicar mayor crawl budget que a las más estáticas. Pero tampoco podemos saber seguro si esto sucede por el tipo de web o por otros motivos (más actividad suele conllevar de forma indirecta más links recibidos y más reindexaciones de contenido -una a una-). Lo cierto es que si recibiras más crawl budget. Ahora bien, que sea una buena estrategia escribir más solo por recibir ás tiempo de proceso de google no lo tengo tan claro. Lo que debes es plantearte si tiene sentido escribir más y luego a parte conocer que esa acción puede tener beneficios paralelos.