Este post surge de unas conversaciones que estoy manteniendo en las ultimas semanas (¿meses quizas?) con Celia de Frutos, donde estamos persiguiendo justo el objetivo de poner orden en los datos de la empresa y disponer de un sistema versátil y potente a la hora de consultar datos. En una de tantos emails me comentó más a modo de broma que otra cosa «¿Y con esto no escribes un post?». Y la verdad es que tenía razón, ¿por qué no hacer un «pequeño» post sobre el tema?.
En este post voy a intentar dar mi visión particular (fuera de libros y teorías varias, que quede claro) sobre como planificar un proyecto de consolidación y centralización de datos. Un paso que a medida que una empresa se adentra en la analítica digital -dejando la web solo como una parte de la misma- resulta lógico y necesario. El proceso, con muchas particularidades de cada caso, suele tener un fondo común. Estamos en una empresa en la que no existe una cultura del dato, muchos departamentos trabajan de forma separada con sus propias herramientas y dejando muchas veces las decisiones más en el buen saber hacer -llamémoslo también intuición- de los seniors. Cierto día, con una chispa que alguien aporta interna o externamente se produce el despertar. Los datos molan. Dan respuestas claras e inequivocas y ayudan a seguir un rumbo positivo en cada aspecto que tocan.
Es hasta divertido ver como a veces son los detalles más insignificantes los que consiguen crear esta consciencia de que los datos hacen falta: un informe bien trabajado, un test a/b, un presupuesto basado en analitica predictiva, una respuesta que nadie había sabido dar hasta ahora o simplemente una formación interna que no se esperaba que cuajase tanto. Eso no es lo importante, lo importante es ese momento en el que la dirección se da cuenta a todos los niveles de que hacen falta datos para tomar decisiones. Y no estoy diciendo que antes no se usasen datos… todo el mundo observa sus ventas y sus gastos, me refiero a todos los datos que explican el camino por el que los macroobjetivos se han conseguido: todo ese conjunto de detalles que permiten crear lo que en analítica llamamos KPI’s y así extraer Insights que expliquen nuestra realidad de negocio.
La necesidad está ahí… ¡Queremos datos! El problema gordo ya está solucionado. Pero ahora tenemos que acercarnos a la realidad y ahí nos daremos cuenta de la gran cantidad de trabajo que tenemos que hacer para disponer de toda la información que queremos. Nos acabamos de meter de lleno en un proyecto de centralización de datos. Será brutal cuando lo acabemos pero el camino no pinta que vaya a ser ni corto ni sencillo… De primeras hay más incognitas que respuestas…

Las necesidades de análisis de la empresa
El primer concepto que debemos resolver es tener claro las necesidades de análisis que va a tener la empresa realmente. Esto no es algo que pueda decidirse en una sola reunión de trabajo y menos aun puede hacerlo un analista o consultor en solitario. Conocer estas necesidades implica si o si reunirse con los responsables de cada departamento implicado y comprender las necesidades de información que tienen, absorber todas sus demandas y transformarlas en métricas y segmentaciones de los datos más relevantes. Es un trabajo de abstracción, de transformación de necesidades en demandas de datos.
Con todas estas necesidades en conjunto es con lo que podremos seguir trabajando dando pasos en la planificación del entorno de datos de la empresa. Sin tenerlas controladas, en cambio, es cuando te encuentras con que a mitad de proyecto o incluso con el proyecto terminado aparecen demandas nuevas que no esperabas; los costes se descontrolan y los tiempos se alargan… Ese tipo de cosas que hace peligrar y poner en evidencia cualquier proyecto. Así que por lo poco que cuesta hacer bien este primer trabajo es importante que todos los implicados se lo tomen en serio y sepan que estas reuniones son para facilitarles su trabajo.
Mi recomendación sería que dieseis al menos 34 pasos en este proceso para llevarlo a buen puerto:
- 1) Identificar a los demandantes de información. A veces jefes, analistas o simplemente profesionales serios e implicados. Quienes deciden con qué datos se trabaja y que necesidades tiene la gente para poder sacar adelante su trabajo.
- 2) Reuniones con recogida de demandas. Si es necesario con cada persona por separado y apuntando cada caso en documentos distintos. Hay que recoger varias perspectivas sobre el negocio y valorar que datos son vitales y cuales prescindibles.
- 3) Consolidación de demandas. Es decir la unión de las demandas de todos en un único documento que nos aproxime al modelo de datos que queremos tener disponible. Buscamos simplificar y concretar nuestro mundo de datos en zonas e informaciones claras.
- 4) Comunicación del esquema consolidado. Es decir, comunicar a esos mismos responsables de forma clara e inequívoca cuales son los datos que vamos a trabajar gracias a ellos.
El ultimo paso creo que es especialmente importante. En proyectos en los que vamos a trabajar mucho tiempo es necesario que existan pactos y compromisos y este tipo de documentos son herramientas ideales tanto para que nos puedan alertar de que vamos a dar pasos en falso como para luego esgrimir el clásico «te lo dije y lo aceptaste» cuando alguien cambie de opinión a mitad de proyecto. Por eso creo que hay que ser especialmente claro con esta comunicación y buscar una aprobación implícita de cada responsable. Técnicas como entender un OK por silencio administrativo no parecen las mejores para estos casos…
Bueno, tenemos nuestro esquema claro. Ahora toca abordarlo…
Planificando nuestro entorno de datos
Aunque situaciones hay miles y realmente hay necesidades que podrán resolverse con las herramientas de las que ya disponemos lo cierto es que debemos pararnos a pensar qué es lo que queremos conseguir y desde ahí planificar qué necesito para hacerlo. Esto nos lleva siempre a un escenario en el que tenemos que dibujar nuestro entorno de datos. ¿De qué datos dispongo? ¿cómo accedo a ellos? ¿Cómo debo tratarlos? ¿Cómo deseo visualizarlos? A todo ese mar de detalles tenemos que ponerle un orden y sobretodo comprendedlo en global para saber por donde atacarlo.
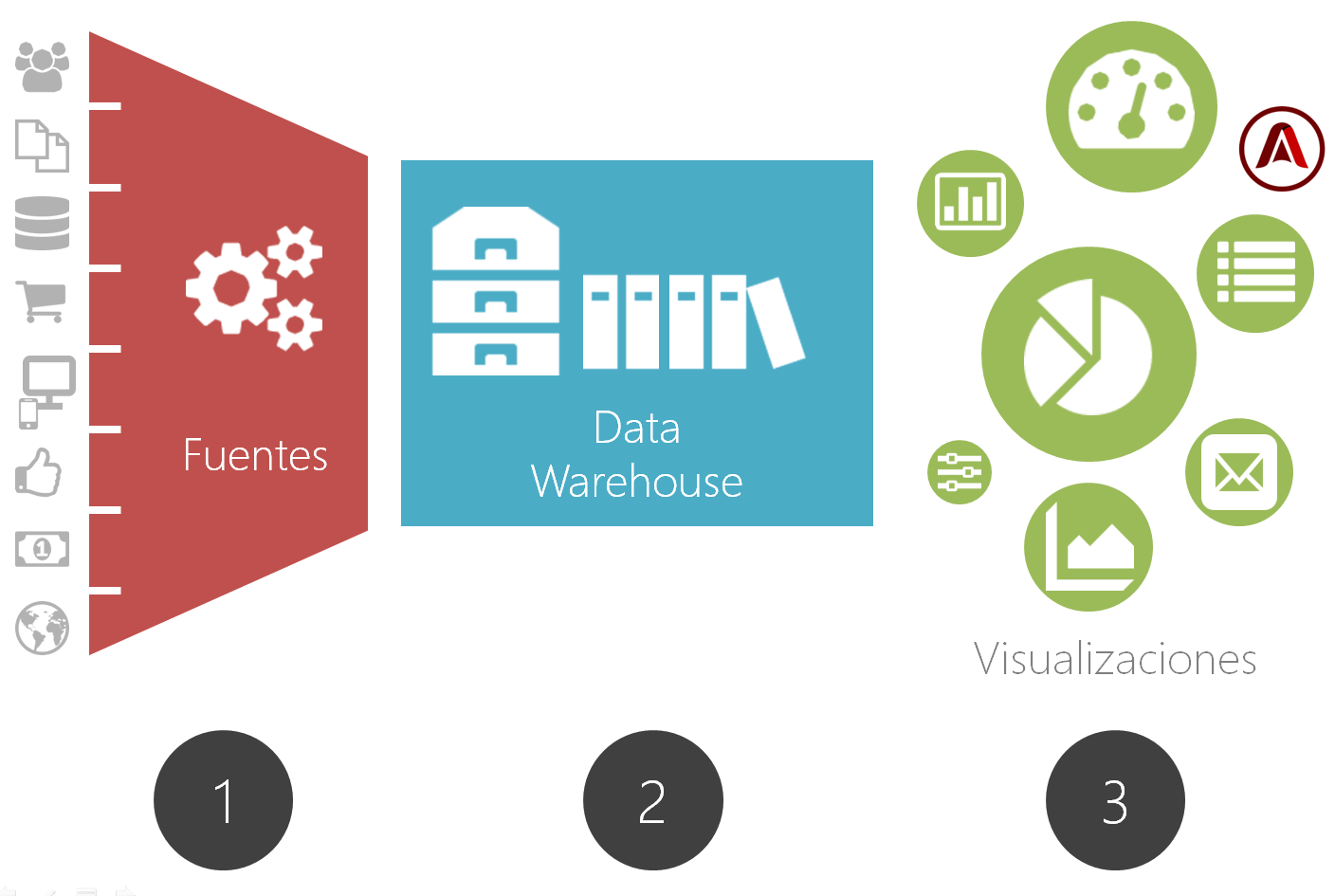
Aquí lo que os propongo es realizar una aproximación dividiendo todo este escenario en 3 zonas diferenciadas de trabajo. Esta división por zonas nos tiene que ayudar a atajar cada tipología de problema de forma más clara.
Las tres zonas de trabajo serían las siguientes:
- Acceso a Fuentes de datos: El sistema por el que accedemos y recogemos los datos de forma sistemática (y preferiblemente automatizada) para poder disponer de ellos.
- Almacenamiento y gestión de los datos: La solución por la que optemos para almacenar de forma interna a los datos (el famoso Data Wharehouse) y así trabajarlos como deseemos
- Visualización los datos: El o los sistemas por los que accedemos a los datos almacenados y terminamos transformándolos en cuadros de mando, dashboards o simples alertas automatizadas
¿Por qué esta separación?
Básicamente porque las soluciones a aplicar y los criterios por los que decidiremos como se conforma nuestro sistema en cada una de las 3 zonas de trabajo es totalmente distinto por lo que cada parte conviene resolverla por separado respondiendo a sus propias preguntas.
En el acceso a fuentes nos encontraremos con problemas como identificación de las mismas, acceso a sus API’s o programación de sistemas de carga de datos. En el almacenamiento tendremos que tomar decisiones sobretodo sobre el soporte a escoger y el formato en el que usarlo. Por ultimo la en consulta de los datos tenemos que a partir del análisis de necesidades de la empresa ver la mejor forma de expresar estos datos para que puedan ser entendidos y accionados por los distintos responsables.
Nuestras fuentes de datos
Saber lo que el mundo de los datos tiene que ofrecernos es esencial. Vivimos en la era de la información y parece que todo este informatizado y medido de una u otra forma pero esto ni es del todo cierto ni la información esta siempre alcance de nuestras manos. Crear un mapa de que información es accesible para nosotros nos ayudará a definir de forma concreta cuales serán nuestras fuentes de datos. Algunas fuentes o datos estarán ahí otras no pero tendremos información accesoria con la que aproximarnos y terminar sacando los mismos insights, otra por desgracia no estará a nuestro alcance.
El siguiente gráfico resume las distintas fuentes básicas de las que deberíamos preocuparnos:
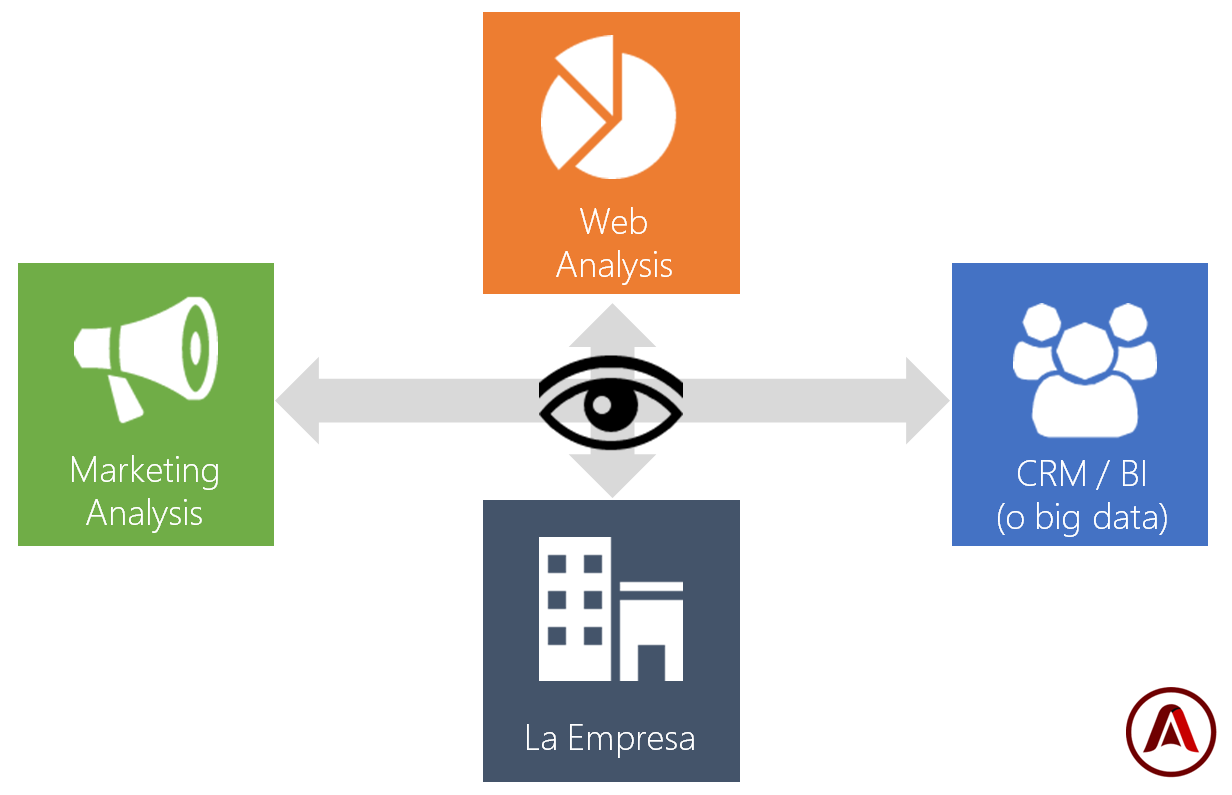
- Las herramientas de analítica: Son información de enorme calidad y si nuestro negocio es una web o una App estaremos de suerte, pues podemos acceder a un mundo de experiencias de usuario de forma bastante cómoda y organizada mediante distintas API’s de datos. Una cuidada selección de KPI’s es práctimente obligada.
- Las herramientas de marketing: Nos suplen de información sobre la atribución e inversión. Nos ayudan a cerrar el círculo y en el caso del online también resultan muy ricas en datos organizados. También es cierto que no toda la información es necesaria para nuestra integración de datos.
- El mundo del cliente y el posible CRM: Suele ser el corazón de la empresa y no podemos despreciarlo. Todo lo que sabemos de nuestros clientes debe ser accesible y si no lo es significa que tenemos trabajo que hacer en capturar esos datos
- Por último tememos información corporativa y de la empresa Que es la que termina de ayudar a dar sentido a los datos y a organizarlos. Aspectos que no forman parte de ninguna herramienta pero que definen la actividad de la empresa, sus departamentos, sus responsables, organigramas, costes y significados. Esta suele ser la información menos accesible de todas, lo que pasa es que como suele ser también la más estable no resulta especialmente complejo tabularla a mano en lugar de importarla como datos electrónicos.
El modelado de datos
Sobre este sistema además tendremos que decidir en qué lugar aplicaremos el modelado de datos. Algo que parece en un principio trivial pero que va a condicionar muchísimo como trabajaremos las distintas zonas de trabajo que definíamos antes.
Llamamos modelado de datos a ese proceso por el cual transformamos los datos brutos que hemos captado de nuestras fuentes en información útil que puede ser consumida y comprendida por los responsables. Es uno de los procesos más típicos del Business Intelligence con sus procesos de ELT o el cada vez más común ETL. Con estos procesos son por ejemplo con los que calculamos cosas como unidades de negocio, departamentos, beneficios, ROI y toda la amalgama de KPIs que hayamos definido.
Este proceso que a priori podría parecer muy simple (a fin de cuentas con exel hacemos operaciones parecidas cada dia en segundos) cuando tenemos que aplicarlo a todo nuestro conjunto de datos uno a uno y disponer de este calculo en segundos (de otra forma nuestros dashboards y cuadros de mando serían infumables) ya no es tan sencillo. Necesitamos de automatizaciones que nos trabajen los datos brutos en el modelo deseado y asi poder trabajar la zona del consumo y visualización de datos sobre el modelo ya trabajado.
Para realizar estos modelos hay distintas tecnologias a nuestro alcance cada una especializada en resolvernos el problema por distintas vías. Algunos ejemplos:
- El famoso Kettle de la suite de Pentaho es al ser open source quizas la herramienta de BI mas extendida. Nos permite dibujar estas transformaciones de forma grafica a base de clicks dibujando flujos de operaciones sobre los datos y exportando el trabajo a realizar hacia archivos java que podamos usar para crear las automatizaciones. Muy bueno para empezar pero muy limitado para grandes operaciones.
- Lenguajes como R se orientan muy bien hacia este trabajo ocupandose de crear el modelo o incluso su visualización. Os dejo la presentación que Jose Ramon Cajide hizo en el pasado User Web Analytics sobre este.
- Python es amado por muchos por ser un lenguaje que trabaja muy rapido con ficheros de texto y procesando grandes volumenes de datos a la vez. Ademas al ser un lenguaje completo que puede orientarse a varios cometidos, no pone limites a que hacer luego con los datos pudiendo así hacer aplicaciones de modelado muy complejas.
- Otros lenguajes. En realidad cualquier lenguaje de programacion es capaz de hacer este trabajo. Lo que pasa es que algunos se comen demasiados recursos del servidor cuando les pides que trabajen con listados de datos muy grandes. Un ejemplo. Nosotros hemos realizado trabajos de importación y modelado de datos con PHP pero dado que en ese lenguaje trabajar con listados de varios miles de datos ya es pesado al final eso te obliga a ir haciendo cada manipulación por fases distintas y no poder hacer todo el modelado del dato bruto en un unico proceso.
- Los lenguajes de bases de datos. El mismo SQL es capaz de modelar en parte los datos e incluso muchos sistema de bases de datos tienen su sistema de programacion asociado (por ejemplo PLSQL) que permite hacer manipulaciones mayores. Sin embargo como antes puede ser muy pesado hacer según que operaciones con ellos.
- Etc. si será por opciones… al final este es un tema tan recurrente que encotnramos cientos de soluciones en el mercado
Lo cierto es que al final qué usar suele depender más del perfil de las personas que trabajan en el entorno de la empresa que de la tecnología idónea o con más posibilidades. Dicho en otras palabras yo no puedo pretender montar un modelado en R si nadie en la empresa va a ser capaz de alterarlo o modificarlo en la empresa o no me caso con un proveedor serio capaz de trabajar en R. Lo mismo para cualquier solución propuesta. Conviene más invertir en aquello que se que puedo controlar.
Decisión 1: ¿dónde debería hacer el modelado de datos?
Y llegamos por fin a la primera gran decisión que tenemos que tomar. En mi esquema de 3 zonas. ¿donde debería realizar el modelado?
No hay respuesta buena a esto y distintos proyectos podrían optar por distintos puntos siendo todos ellos correctos. Lo que si puedo explicaros es que implicaciones puede tener hacer el modelado en distintos puntos del esquema.
1. Modelado en la carga de fuentes. El proceso ETL
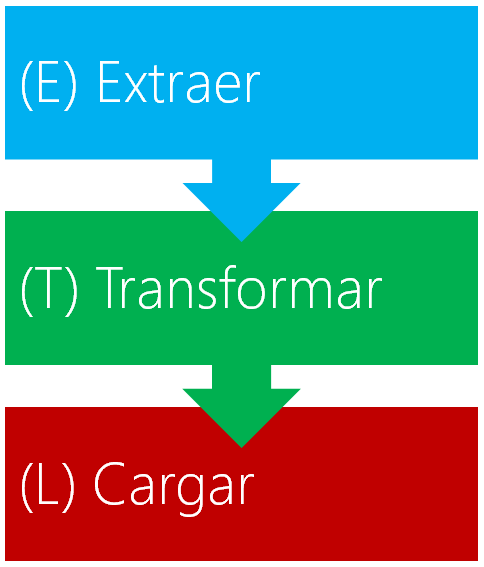
Esto implica que el mismo proceso que se encarga de ir a recoger el dato a la fuente es el encargado también de modelar los datos para que ya sean guardados en un esquema fácil de consumir. Es lo que en BI se conoce como ETL (Extraction->Transform->Load)
Implicaciones: De primeras esto supone que la construcción de las cargas de datos de las fuentes se compliquen. Ya no solo tengo que conectarme a una API (por ejemplo analytics, Twitter, etc.) o base de datos (CRM, base de datos interna, etc.) Sino que además tengo que procesar lo que saque de ahí para que los datos sean casi los que quisieramos ver en un cuadro de mandos. Luego esos datos son los que llevo a mi sistema de almacenamiento de datos (alias datawarehouse) para que en este sistema ya tenga directamente el modelo bien clarito.
Ventajas de este sistema: La ventaja es que acumulo la parte de inteligencia de negocio en el acceso a los datos provocando que solo la zona de carga de datos sea compleja. Esto en algunos sistemas con una explotación no tan al detalle de los datos es una ventaja pues reduce sensiblemente los costes del proyecto. Así sólo necesito un equipo de trabajo o un proveedor que me cree las automatizaciones de la carga y modelado de fuentes, a partir de ahí los datos ya están disponibles de una forma que cualquiera del equipo interno de IT o cualquier software de visualización de datos va a poder aprovechar sin demasiadas operaciones.
Problemas de este sistema El problema surge precisamente por esa acumulación de la complejidad en un único punto. Las cargas de datos son realmente potentes pero precisamente por eso cuando alteramos el modelo de datos se vuelve más costoso. Por un lado tengo que revisar mi proceso de carga incluso cuando no necesito datos nuevos y solo quiero procesarlos de otra forma (cambio en el modelo) pero peor aun es que como el dato bruto no lo he guardado sino que solo he almacenado el dato modelado un cambio en el modelo supone siempre rehacer todos mis datos almacenados. Es decir, si llevo un año almacenando datos en un modelo y lo cambio, tendre que volver a generar todo ese año de datos de nuevo.
¿Cúando usarlo? Como decia, es ideal cuando no quiero asumir internamente demasiados procesos y que se genere el proyecto con un coste comedido. Pero más aun es interesante cuando se que mi modelo de datos no va a sufrir demasiadas variaciones en el futuro. Cuando las bases de analisis están suficientemente asentadas y la gente que cosume los datos es suficientemente seria como para no generar una continua recarga de los datos modelados.
2. Modelado en el almacenamiento de datos. El proceso ELT
Esta es la forma más común en entornos Big Data que son capaces de procesar ingentes cantidades de datos en sus sistemas en tiempos ridículos. Pero también es un sistema más que posible fuera de estos entornos. La base es sencilla. Mi almacen de datos se va a ocupar de mantener dos copias de los datos: por un lado cargará los datos brutos desde las fuentes sin ningún procesado (lo que supone muchos más datos a guardar) y por otro un proceso interno automatizado hará replica de esos datos en la versión modelada (o incluso en algunos sistemas, el modelo será directamente el proceso que calcula los datos desde los brutos en cada petición realizada). En BI hablaríamos de procesos ELT (Extraction->Load->Transform)
Implicaciones: Ni que decir que el sistema crece mucho en complejidad y recursos. Estamos hablando de montar un almacen de datos brutal con todas sus fuentes de datos ahí metidas (WATs, herramientas de marketing, bases de datos de la empresa, etc.) y además queremos autoprocesar esos datos para disponer de ellos ya modelados. Es decir, estamos montando una bestia de proceso. Pero eso sí, una bestia capaz de darnos lo mejor de todos los mundos.
Ventajas Las ventajas son más que evidentes. El entorno es capaz de almacenar todas las fuentes al detalle con lo que evitamos recargas de datos históricos, al mismo tiempo el proceso se automatiza lo que implica que cambiar de modelo es solo cambiar detalles de ese proceso desde el dato bruto al modelado y el automatismo hará el resto. Por ultimo las herramientas de visualización siguen disfrutando del dato modelado y por lo tanto fácil de acceder para todos.
Desventajas Montar estos sistemas suele ser mucho más costoso tanto en recursos (económicos y de personal técnico) como en tiempo. Hablamos de proyectos que se pueden ir a más de uno o dos trimestres si las cosas no están muy acotadas. Es decir, estamos apostando muy en serio por la centralización de datos.
¿Cuando usarlo? La respuesta corta sería: Cuando vamos en serio. La larga tiene muchas implicaciones, ¿Cuantos recursos puedes destinar? ¿Que rentabilidad esperas sacar del proyecto? y más importante aun, realmente ¿cuanta gente va a hacer un uso real de todo lo que estas montando? Aquí mucho cuidado. No seríais los primeros que van a por todo para descubrir que una vez acabado el proyecto solo 2 o tres personas lo usan y sus informes luego no son tenidos en cuenta por la dirección… Lo dicho, lo de gastar recursos de verdad dejemoslo solo para cuando vayamos muy en serio. Eso si, una vez lo tengamos, seremos muy muy felices.
3. Modelado en la consulta de los datos
Por último y de forma más común de lo que la lógica nos podría llevar a pensar esta la posibilidad de almacenar solo el dato bruto y dejar a la herramienta de consulta de datos que sea ella la que cree el modelo necesario para realizar su visualización. Esto viene a ser que tan solo nos tenemos que preocupar de tener el dato limpio y que relegamos a una herramienta el trabajo duro. Es decir, la antítesis de lo que sería procesar en la carga.
Implicaciones Lo primero que nos ponemos en manos de la herramienta de consulta de los datos y por lo tanto tenemos que conocer como trabaja esta. Por lo general estas herramientas se venden por su capa visual con un alto efecto wow en la decisión de compra. Pero la realidad es que importa mucho más que capacidad de tratamiento de los datos van a hacer. Si por ejemplo esperamos que una herramienta sencilla y barata sea capaz de absorver nuestros datos en bruto y procesarlos en tiempo real vamos listos. Lo que suelen hacer las herramientas que posibilitan el modelado en sus propias tripas es copiar nuestros datos en bruto (una copia de nuestro datawarehouse) y realizar el modelado en otra fase (como en el punto anterior) para así darnos la misma velocidad que si hubiésemos trabajado en ese entorno profesionalizado del que hablábamos antes. Esto es genial, pero otra vez no es barato.
Ventajas Por un lado tenemos la ventaja de desplazar a un punto normalmente externo a la empresa la complejidad de los procesos. Nuestra capa de carga de fuentes y de almacenaimiento puede llegar a ser realmente simple. Por otro lado la variabilidad del modelo final usado ya no es problema, a base de clicks y configuraciones reviso mi modelo cuando lo necesite.
Desventajas Tendríamos como desventaja el duo de precio-funcionalidades que suele ir bastante de la mano. A un bajo precio no podemos pretender que la capacidad de modelado de la herramienta sea muy alta lo que significa que le tendremos que dar los datos ya masticados. Para cuando llegamos a funcionalidades realmente interesantes vemos que hemos pasado sin problemas la franja de los 1000€ al mes de coste. Otra de las desventajas evidentes de este sistema es que si dejas en una herramienta la inteligencia de los datos significa que solo puedes usar esa para ver los datos y no puedes apoyarte en distintas herramientas para ver los datos de distintas formas.
¿Cuando usarlo? Personalmente no me acaba de convencer este sistema porque la capa de visualización es una de las más volátiles y que más flexibilidad debería darnos. Si me caso con una herramienta (que no un proceso propio) cuando esta ya no me sirva o no sea suficiente tiraré todo el trabajo que hice con ella. Aun así, es más que recomendable cuando tenemos muy claro que los datos se van a disfrutar mayoritariamente a través de esa herramienta y esa decisión la llevamos arrastrando desde la primera parte del proyecto (las demandas de los responsables).
Decisión 2: ¿De quien son los datos?
Una decisión que a mi personalmente no me importa nada. Soy confiado, que le vamos a hacer. Si firmo que una empresa no va a mirar mis datos, entiendo que no lo va a hacer…
Sin embargo este es un tema que preocupa a muchas empresas y no hay que olvidar que cuando montamos todo esto no esperamos ver ahi dentro solo datos de analítica sino que vamos cargar dentro datos de costes de campaña, ingresos, beneficios e incluso puede que costes de personal y estructuras. Son datos muy sensibles y ya no solo porque lo diga la LOPD sino porque para según que competencia podrían ser muy apetitosos… y ahi lo dejo, del terreno ideal no hace falta que os explique demasiado.
Asi pues en todo este flujo de la información debo tomar una decisión muy importante sobre quien puede acceder a mis datos y que pasa con ellos. Esto afecta sobretodo al datawarehouse y posibles replicas que se hagan del mismo. ¿Tenemos la necesidad de que la información quede controlada? y de ser así ¿Sabemos exactamente quien accede a cada aspecto de nuestro negocio?
Este tipo de decisiones no aportan nada a cómo debo montar mi estructura pero si limitan nuestras posibilidades. Por daros el ejemplo más evidente. Si me niego a meter mi facturación en servicios externos, olvidémonos de cualquier servicio de Big Data en cloud, sencillamente no podemos hacerlo porque no nos vamos a fiar de ellos. Olvidémonos también entonces de esas herramientas que replican nuestros datos y cubrámonos bien por contrato sobre como acceden a la info a las que les damos acceso. Si tampoco lo tenemos claro así eso implicaría comprar licencias de software instalable, o instalar software opensource en nuestros sistemas o crear nuestro propios sistema de reporting… Ninguna decisión es trivial.
Decisión 3: El soporte usado. ¿Entramos en Big data?
Debemos admitir que el Big Data esta de moda. Quizás demasiado de moda… Pero ¿Qué es Big Data? Como sistema, no es más que un conjunto de tecnologías que posibilitan el procesamiento de datos muy granulados en tiempos record. Solo eso. Por asombroso que nos resulte hasta donde estamos llegando en capacidad de generación y proceso de datos en estos días la realidad es que por si solo el Big Data no aporta ninguna inteligencia ni nos va a dar soluciones directas. Al final se trata de bases datos como las que llevan usandose ya muchos años solo que ahora con una capacidad de trabajo bestial.
Y en realidad la linea que separa que algo sea Big Data o simples bases de datos conceptualmente es muy difusa. Todo el mundo se cuelga la etiqueta de Big Data a veces sin aportar ningún valor especial a sus servicios. Encontraremos quien nos diga que todo lo que no quepa en un excel es Big Data. Segun esa definición una base de datos de 500.000 productos sería big data… También quien nos hable de que Analytics es Big Data, y lo es… pero la parte que nosotros usamos de él yo no la veo como Big data real. Para mi tenemos que hablar de servicios capaces de manejar grandiosas cantidades de información, casi sin limitación. No hablamos de 500.000 productos sino de 500 millones, con todo el histórico de stocks de los últimos 10 años, de compras y de incidencias. También debemos hablar de libertad total de consulta de estos datos. Si los datos ya se guardan procesados y solo puedo consultarlos por una API o sistema limitado no creo que debamos hablar de Big Data. Sin estas ventajas incluso usando bases de datos orientadas a big data, no creo que debamos ponerle ese nombre. Al final la formula es clara:
Big Data = Muchísimos datos al detalle + Proceso en tiempo real de los mismos.
Decíamos que Big Data es solo un sistema con ventajas de almacenamiento y proceso pero no debemos olvidar que el trabajo sobre entornos Big Data en cambio si que tiene ciertas ventajas sobre el trabajo tradicional en bases de datos o archivos sueltos. Y es que a un precio no desorbitado (aunque tampoco barato) podemos disponer del dato granulado y procesarlo en tiempo real. Esto tiene ciertas implicaciones positivas y negativas.
- El big data fuera de entornos en la nube puede hacerse pero es bastante caro y también caro de escalar: Implica que montes una batería de servidores en tu web y que les instales un software de pago para hacer el trabajo. La capacidad de proceso que te de este Big Data dependerá de cuanto quieras invertir en este sistema base. Por otro lado los entornos en la nube suelen ser más rápidos de preparar y económicos pero como hablábamos en el punto anterior no son posibles si no queremos meter en servidores de otra gente datos sensibles.
- Big data permite procesar todo o parte del modelado de datos en tiempo real. Eso simplifica mucho las variaciones sobre el modelo y por lo tanto es ideal para soluciones donde el modelado se haga en la zona de almacenamiento de los datos. En estos sistemas si podemos aprovechar las ventajas del big data al llevarnos los datos casi desde la fuente a la visualización en el justo momento que los pedidos.
- Esto último no sucede siempre. Hay veces que incluso el Big Data será demasiado lento o su proceso no sera suficiente como para hacer el trabajo y tendremos que hablar de modelados del dato incluso dentro de entornos big data. Como siempre depende de lo que pidas (o de lo que los depmandantes te hayan pedido).
- Big data no aporta muchas ventajas sobre datos ya modelados. Por ese motivo no tiene tanto sentido cuando hablamos de modelados en la fuente (salvo que la cantidad de datos a procesar incluso estando modelados sea descomunal). Ahi bases de datos convencionales pueden hacer el trabajo sin problemas
Con todo esto deberías decidir si el Big Data es o no para tu proyecto, asumiendo que cuando una tecnología no es necesaria hay que ser serios y quitarla de la ecuación. Tu proyecto no será peor que otro por no usar big data. Es más seguramente será más eficiente solo por el estudio que has hecho para determinar que a ti no te hacía falta usar Big Data.
Y por último, decisión 4: El caos de herramientas
Una vez y solo una vez tengo todo lo demás claro es cuando puedo acercarme a la amplia oferta que se está desarrollando sobre este tipo de trabajos. Y ahi vamos a encontrar de todo. Ciertos productos como pueden ser Google Big Query, Qlick o Tableau pueden destacar (en fama y funcionalidades) por encima de otros pero la realidad es que tenemos que buscar los que mejor se adapten a las necesidades que ya hemos detectado y definido en los pasos anteriores.
Lo que siempre va a ser un error es empiezar un proyecto de este tipo eligiendo antes que nada la tecnología.
Esta debe ser una consecuencia, no un requisito. Aun así no son pocos los proyectos que nacen con la premisa «vamos a meter un tableau» o «el objetivo es meterse big data». Sin saber ni si lo necesitas estas condicionando tus necesidades y puedes terminar teniendo suerte pero tambien puedes tirar el dinero a la basura y eso en el mejor de los casos…
El caso ideal sería pasar por ese escenario del que os hablaba antes:
– Tengo claros los requisitos
– Entiendo el modelo de datos que quiero comsumir
– Conozco mis fuentes de datos y se como implementarlas
– Defino el sistema de almacenamiento de datos
– Defino los modos y visualizaciones por los que quiero ver los datos
– Especifico donde y cómo quiero hacer el modelado de datos
– Y entonces, elijo las herramientas que me faciliten la carga, almacenamiento, proceso y visualización de los datos en las condificiones que he especificado (o en las mas cercanas, siempre algo se nos atascará)
El problema de ubicar las herramientas en nuestro esquema
Para terminar de complicar todo esto me voy a encontrar con que las herramientas no se sitúan casi nunca en una de las 3 zonas de trabajo que definiamos (carga de fuentes, almacenamiento y visualización) sino que todas han cogido lo que creen que es más competitivo para su oferta de servicios y cubren mejor o peor varias necesidades. Por lo general muchas te ofrecen ocuparse del almacenamiento y procesado con algunos extras.
Algunos comentarios sueltos sobre algunas herramientas. No porque sean las mejores sino por que son las primeras que me vienen a la mente:
– Google Big query: se ocupa del almacenamiento de datos, como herramienta big data es capaz de crear el modelo en tipo real o procesandolo. Ademas integra directamente en Google Analytics Premium los datos (haciendo innecesaria la carga de la fuente). En este caso nos han hecho incluso trampa en Google y resulta que Google Big Query es la única forma rápida de sacar sin muestrear grandes periodos de tiempo (la api nos da su famoso muestreo) de GA. Asi que incluso es posible que uses Big Query no como herramienta Big Data de almacenamiento sino como Fuente de datos. Es raro que uses una herramienta en teoria Big Data como fuente, pero pasa más de lo que podrías pensar. Esto es culpa de Google. Si nos diese un acceso API a Google Analytics sin muestrear para cuentas premium esto no pasaría pero obligandonos a pasar por Big Query si o si desplaza la balanza en su favor. Quiern que nos hagamos preguntas del tipo:; «¿Si total, ya estoy en Big Query? porque no usarlo como data wharehouse».
– Google Data Studio 360: la nueva aplicación dentro de Google 360 Suite parece orientada a conseguir la visualización también desde el propio Google Big Query absorviendo 2 zonas ella sola. No solo eso sino que parece que podrá acceder directamente a fuentes y hacer los modelados de datos por si sola. A ver al final si es verdad…
– Qlik y Tableau: se pueden ocupar cada uno por su lado de almacenar los datos, procesarlos (en la medida de lo posible) y mostrar la representación gráfica. Ambos tienen varias opciones entre las que la diferencia principal radica entre escoger un sofware personal de escritorio, una solución desde tus datos o una versión totalmente cloud con los datos también almacenados por ellos. Pueden usarse por lo tanto solo para visualización o también como datawarehouse vitaminado. Además tiene funcionalidades para hacer visualización directa de las cargas de fuentes (cargas muy sencillas, eso si, no les pidas gran cosa).
– Pentaho: Es una suite muy completa capaz de dar todos los pasos por si sola, pero también al estar dividida en herramientas independientes nos permite usar solo algunas de sus opciones sueltas para carga modelado o visualizacion de datos.
Las opciones son interminables…
Conclusión
Creo que los que nos dedicamos al marketing online muchas veces no somos ajenos al marketing que hacen otras empresas. El Big Data esta de moda y las herramientas que se ponen el sello del big data no para de proliferar pero en muchas ocasiones se pierde la esencia de por qué requerimos de estas herramientas. Al final todo esto del Big Data no es más que una serie de herramientas más y las herramientas sin un motivo fundamental solo nos hacen perder el tiempo. Pensemos y planifiquemos lo que necesitamos y a partir de ahí las herramientas saldrán solas.
4 respuestas a “Proyectos globales de datos, una aproximación a desarrollos Big Data y Data Warehouse”
Me alegro de que te hayas animado a sacar este post a la luz. Hubiese sido una pena que una explicación tan bien hecha se hubiese quedado solo en un cruce de emails.
Muchas gracias por compartir tus conocimientos y por hacernos más terrenal el mundo del Big Data. 🙂
Gracias por el artículo, reconozco que no me lo he podido aún leer en profundidad. Me estoy adentrando en el mundo de la analítica y me gusta el enfoque del sistema que has ofrecido en este escrito. Salu2.
Gracias Iñaki. El valioso tiempo que has dedicado a escribir esta clarificadora explicación de por qué necesitamos datos y plantearnos qué queremos hacer con todos esos datos, como los vamos a recolectar, guardar y visualizar bien merece difundirlo con un RT, no sólo un Like ( como parece ser la moda ahora ).
Un post muy clarificador Iñaki, me lo he leido con calma (libreta en mano) y me ha servido como checklist perfecta para arrancar y contrastar una propuesta de BI. Especialmente de acuerdo en dos puntos: apuesta por la propuesta de desarrollo que sea más sostenible ne la organización y adecua la complejidad a los usuarios y perfiles reales que vayan a sacarle partido.